株式会社ブロードは企業のIT運用の効率化とセキュリティ向上を支援しています。
![]()








SWIM.AI
新しい世界の到来、現時点での今の状況認識が重要。
大規模なスケール展開で、永続的な、切れ目ないインテリジェンスをSWIMは可能にする。
イントロダクション
「ビックデータ?いや、今はエンドレスデータだ」
SWIM.AI社CTO、Simon Crosby氏ブログ記事 ”Big Data? No, It's About Endless Data Now.”より
今世紀の始めごろ(ITの世界では大昔だが)Googleから2人の天才がエンタープライズのビッグデータをうまく扱うレシピ、Hadoopを持ってスピンアウトしました。Googleにとって上手く動いたのだから、それは企業が必要とするものだってことですよね。ClouderaとWortonworksはエンタープライズのアプリケーションの当面のプラットフォームはビッグデータの湖であるとのアイディアを進化させました。
しばらくの間は特定のアプリケーションに関しては、それは有効でした。両社ともIPOを成し遂げ、そしてすぐに、この動きに続いた他の大手クラウドベンダも各々のビッグデータソリューションを提供し始めました。
しかし多数のデバイスがクラウドに繋がりだすや、データの小川の流れは洪水に変わりました(こんにちでは毎時2Mのレートでコネクションがある)。そして多くの組織はビッグデータを稼働させられる唯一の場所はクラウドだと気づき始めました。しかもPowerBI(Azure)やSprakおよびFlinkなどの強力な分析ソフトウェアフレームワークは「サービス」として利用する方が容易であるとわかってきました。HortonWorks社はCloudeaに買収されましたが、その躍進は多数の企業がオンプレでデータの湖を扱うことに、嫌気がさしてきたことに比例しています。
問題は、「保存してから分析する」哲学であり、これが限界にきていることです。オンプレでの提供か、サービスとしてか、ではありません。
世界で何十億ものデバイスが繋がる非常に動的な環境では「データベース指向のアプリケーション」は正確、詳細、かつ継続したコンテクストを持つインサイトの提供は不可能です。アプリケーションやユーザが現時点の状況を詳細にリアルタイムで必要とする場合(例UBER)連続的にデータを分析し、何が変更され、そのうち何が関連する情報か、どのように今後を予測するか、そしてどう対応するかをプロセスしなくてはなりません。問題はデータではなく、またデータの分析でもなく、リアルの世界をリアルタイムでどう理解し、相関するかになります。
CPUより何千倍も遅いディスク上の保存データにアクセスし、あるいは分散データベースへアクセスする事は、パフォーマンスと連続性の問題につきあたります。さらに境界線のないデータを保管するのは非常にコスト高です。しかし、これ自体が課題なのではありません。
必要なことは、何十億という境界のないデータストリームをリアルタイムで継続して処理することです。対象のストリームは、この時空間で相互に動的にコンテクストの相関性を保持するデータの発信源から送られてきます。
目標は、この実世界の情報を理解して対応する必要があるユーザやアプリケーションにインサイトを提供することです。レガシー、あるいは「複雑なイベント処理」の独自アプケーションスタックでは対応できません。なぜならば、それらは単一のアーキテクチャで固定されたネットワーク上のデバイスから流れてくる、固定のデータストリームに関する単一の問題を解決するようにデザインされているからです。
全てのタイプのモバイルデバイス、製品、インベントリあるいは人までもがスマートインフラ内を行き来します。従って、これまでのような「スキーマベースのリレーショナルデータベースモデル」ではフィットしないのです。プロキシメティ(関連範疇)、包含性、類似点さえも動的です。なぜならば、実世界は変化し、物事の状態も変化するからです。
新しい世界を正しくモデリングするには、この動的な変化するデータ源間のグラフ(常に関連が作成されては壊される)に対応できるアプリケーションアーキテクチャが必要であり、そのアプリケーションがコンテクスト状態を理解し、相関性を意味を持った情報に転換し、ユーザに価値のあるインサイトを、またそれをリアルタイムで提供できることが必要なのです。
SWIM.AI社CTO、Simon Crosby氏によるSWIM.OSのより詳しい解説資料のダウンロードはこちら
別サイトBROAD Security Square(BSS)にジャンプします。
製品の特徴
ストリーミングデータをリアルタイムのインサイトに活用
分散、拡大されたエンタープライズ向けのDataFabric(データファブリック)
【なぜ今DataFabricなのか】
- 非常に効率的
DataFabricは WebSockets、MQTT、Kafkaを利用して、エッジデバイスやストリーミングインフラからデータを取り込み、ローカルやクラウド上でのコンピューティングを最適化します。
- リアルタイムでの解析
DataFabricはリアルタイムAPIと可視化により最新のインサイトを連続的なストリーミングデータの速さで結果を生成します。
- コストの削減
簡易であることと高パフォーマンスが同時成立しないという懸念は無用です。DataFabricは既存のデータフローパイプライン・ソリューションで必要とされるリソースのほんの一部しか必要としません。
【変革的なアプローチ】
- インフラから始める
今日のデータプロセシングは「保存して解析する」というビッグデータ時代に築かれたアーキテクチャをベースにしています。 つまりデータはまず収集され、そして中央のデータ保存場所に送られ、後で処理されます。 このようなアプリケーションは非常に高価なインフラ(オンプレまたはクラウド)上に構築され、データサイエンス専門家が複雑で脆いモデルをデザインする必要があります。 脆いというのは、運用環境内の予期しない条件変更、例えばデータフォーマット、データ容量が、運用あるいはアプリケーションの障害を引き起こす可能性があるということです。 結局、古いデータから引き出されるインサイトは利用価値が限られており、ビジネス環境での応答や対応をタイムリーに提供できるように継続したインテリジェンスを戦略上必要とする今日のニーズは満たしません 。
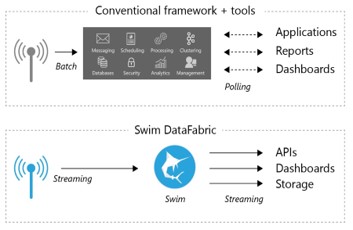
- 対して インサイトから始める
DataFabricはアプリケーションの複雑性、インフラおよび運用コストを画期的に減らす一方で、インサイト提供への時間を早めます。 エッジデバイスからクラウドまでの利用可能なコンピューティング能力を活かし、インフラの制約を超えて、ストリーム内のデータを解析して意思決定へのスピードを早めます。
【エンタープライズにとってのビジネス上の価値】
- コスト削減
ストリーミングデータを既存のローカルのコンピューティング資源で処理することでクラウド運用にかかる定額コストを下げられます。
- 効率の向上
データの生成元でデータを変換することで、ダウンストリームのクラウドアプリケーションがコンテクストリッチで構造化されたデータを取り込めます。
- リアルタイムのインサイト
DataFabricのストリーム最適化ネットワークスタックを利用し、インサイトの検出および配布がネットワークスピードで提供されるようになります。
- どこでも実行可能
DataFabricは制限が多いエッジ環境やまたはクラウドのインフラ環境でも実行可能な柔軟性を備えています。
- インフラは軽く
DataFabricはアプリケーションロジックに依存せず、アプリケーションインフラに自動的に対応します。
- クラウド統合
DataFabricはコンテナ化され、Azure Marketplaceを含むクラウド環境に展開することが可能です。
【オープンソース上に構築】
- SwimOS 唯一のリアルタイムアプリケーションプラットフォーム
SwimOSはデータベース、メッセージブローカ、およびアプリケーションサーバの必要なくアプリケーションを開発、実行できるように単一で統合されたソフトウェアスタックをエンジニアチームに提供します。 DataFabricはこのswimOS上にビルドされ、レジリエンス、スケーラビリティ、ビジュアライゼーション、展開のための追加機能が含まれます。
- Swimはスケーラブルでエンドツーエンドのストリーミングアプリケーションを構築するための完全に統合化されたソリューションであることを念頭にデザインされています。 別々のメッセージブローカ、アプリケーションサーバ、データベースを構成する代わりにSwimは独自の存続性、メッセ―ジング、スケジューリング、クラスタリング、レプリケーション、イントロスペクション、およびセキュリティを提供します。
- Swimは利用可能なコンピューティング資源の活用を自動的に最適化してローカルでデータを生成します。 つまりリアルタイムのパフォーマンスに影響与えず、ストリーミングデータを活用した非常にスケーラブルなアプリケーション構築を可能にします。
【Swimとは?】
- 分散オペレーティングシステムのようなもの
第一原理から社内で開発されたSwimは大規模に分散されたリアルタイムアプリケーションを構築する際の課題を包括的に解決します。
- ストリーミングWeb
分散アプリケーションを透過的に相互継続するために、SwimはHTTPをWARPと呼ばれる継続した一貫性を持つマルチプレックスなストリーミングプロトコルにアップグレードします。
- ユニバーサルなランタイム
小型の自己完結型ランタイムであるためSwimは一般的なエッジデバイスから大型サーバクラスタ、またはその間に存在する対象に対してアプリケーションを透過的に展開させることが可能です。
- 実際のユーザエクスペリエンス
人間はリアルタイムの存在です。意識の連続が生活として経験されます。SwimのストリーミングUIフレームワークはアプリケーションを実際に我々利用者が行動するように実行可能にします
【以下のような課題を解決します】
- コストの上昇
ゲートウェイやストレージに始まり、ほとんどの企業は増加するデータを収集する以前からすでにインフラコストが発生しています。
- データサイエンス専門家のリクルーティング
え社内の人材は不足していなくても大規模なデータセットをクレンジング、オーガナイズ、モデリングするチームを結成するのはどのような企業にとっても課題です。
- 永続的な複雑性
今までのアプローチ方法で大規模なデータセットを収集、移管、保存そして解析するのはアーキテクチャ的に非常に面倒を引き起こします。
- 高価なサポート費用
ソリューションをメンテナンスするために、DevOps、インテグレーション、ネットワーキング、アナリティック、そしてカスタマサポートが一体になった総合チームが必要になります。。
- エンタープライズに対応昇
DataFabricは様々な分散環境をまたがり、リアルタイムインサイトを提供することが実証されています。 センサー、デバイス、システムのような実世界のデータソースを表すために、そのデータからステートフルオブジェクト(あるいはデジタルツイン)のライブのグラフを自動的に作り出します。 DataFabricはその後に安全なコネクションの網を通じて一貫性を保持するためにこれらのオブジェクトを動的に連結します。 リアルタイムデータが生成されると、これらのオブジェクトは処理、分析、対応、および予測を行い、DataFablic全体およびAPIを介して外部からインサイトを利用できるようにします。
事例
| 資料請求はこちらから | 資料ダウンロード SWIM.AI社CTO、Simon Crosby氏によるSWIM.OSのより詳しい解説資料はこちらからご請求下さい(別サイトBROAD Security Square(BSS)にジャンプします)。 |
|---|